
Methods
In June 2007 Julian McGlashan and Cathrine Sadolin performed an endoscopy study at CVI in Copenhagen.
Twenty-one singers (ten males and ten females) trained in the Complete Vocal Technique were recruited and asked to produce a sustained vowel in each mode. Each singer was instructed to produce the mode as perfect (near to the centre of the mode) as possible with minimal additional effects, twang and extremes of sound colour. The larynx was imaged using a videonasoendoscopic camera system (OTVS7 camera and ENFV2 videoscope from Olympus/Keymed) and the Laryngostrobe system (from Laryngograph Ltd) used for image capture.
Three subjects were excluded as they could either not tolerate the examination (1) or the image quality was not adequate for interpretation (2).
When looking at these videos certain patterns were seen in the laryngeal gestures within each mode. A still image for each of the modes was produced from the videos. The still images were chosen by listening to the sound without seeing the images and extracting the stills when the sound was as close to the centre of the mode as possible.
Each set of five (Neutral with and without air were viewed separately) video images were analysed by Julian McGlashan and Cathrine Sadolin and the appearance and relationship between the key anatomical features was agreed by consensus and documented. The consistent features were identified and schematic drawings produced with descriptive and explanatory text to aid pattern recognition.
Then these laryngeal gestures were schematized by the most obvious gestures (the ’first glance’) and then further examined and categorized into what could be seen at a ‘second glance’.
We gave the various parts in the vocal tract levels in order to identify and specify on which levels the various changes take place. The levels also make it easier to communicate where the changes take place. On the stills from the footage only the first 3-4 levels are seen.
To indentify the structures on the endoscopic images see the anatomy of the larynx.
‘First glance’ features on the laryngeal gestures in Neutral with air on the levels are:
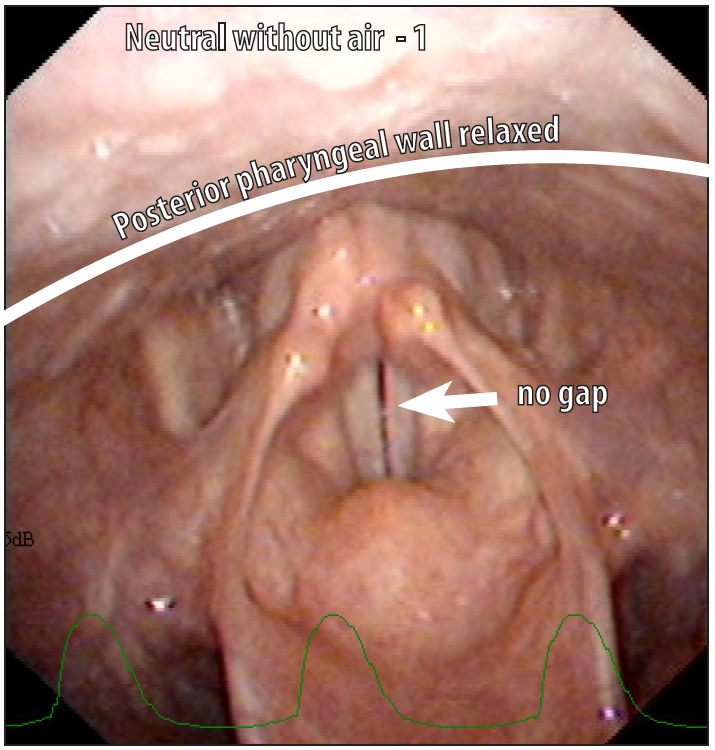
Level 1
- Glottic gap along vocal folds, greatest posteriorly
- Vocal folds seen along their entire width posteriorly
- Vocal folds seen along most of their length
Level 2
- False cords retracted laterally (concave appearance), more so posteriorly
Level 3
- Arytenoids held together (no gap between them)
- Posterior wall of pharynx more relaxed and rounded
In everyday language:
You can see the vocal folds clearly as the false folds are retracted and there is no gap between the vocal folds. Note that during stroboscopy with a rigid endoscope that it might sometimes look like there is a gap between the folds, but this has to do with where in the point in the vibratory cycle when the picture has been taken as it disappears when the vocal folds are in contact. In Neutral with air there is a persistent gap throughout the vibratory cycle.
The back wall of the larynx is relaxed leaving the larynx open so you can see the vocal folds and false folds easily.
‘Second glance’ laryngeal obvious gestures in Neutral without air on the levels are:
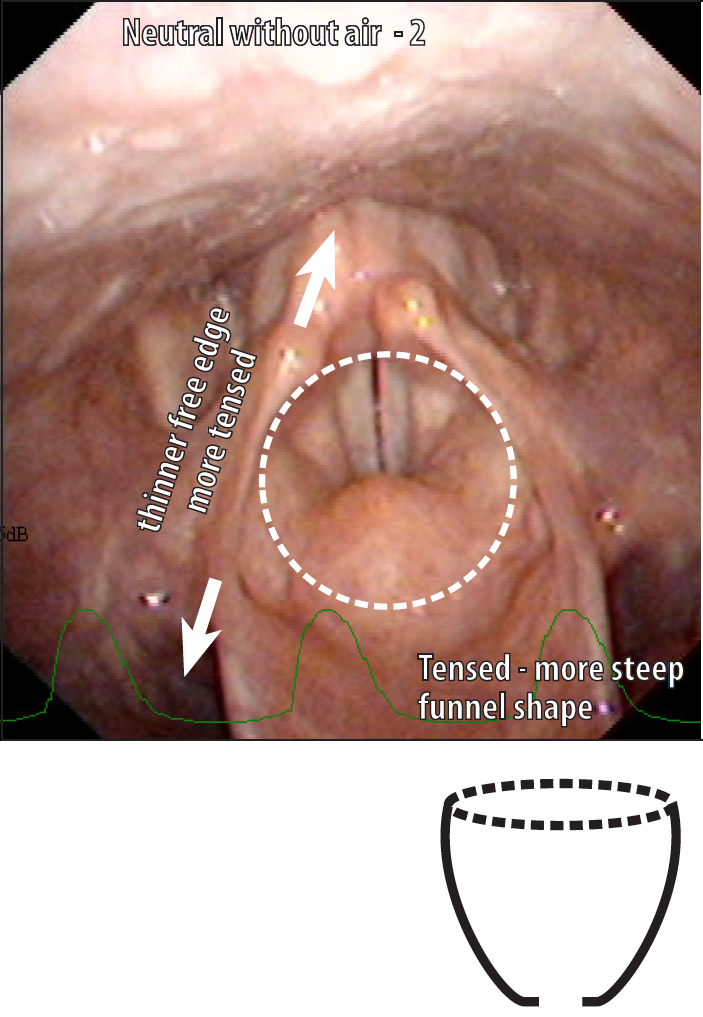
Level 2
- Laryngeal inlet has inverted pear shape at false fold level
Level 3
- Cuneiform cartilages not overhanging false folds at all
- Aryepiglottic folds stretched and have a sharp edge turned slightly inwards
- Epiglottis rounded
- Acute angle of apex of arytenoids
- Can see pointed apex of arytenoid
- Gap between the arytenoid apex and posterior pharyngeal wall
Level 4
- Piriform sinuses more triangular shaped and open
- Supraglottis is open and funnel shaped
In everyday language:
The Aryepiglottic folds are tense and stretched more so they becomes thinner.
The opening of the larynx has a shape of an more tensed funnel which is steeper than in Neutral with air
The laryngeal gestures in Neutral without air without drawings

This information comes from a study Visual Vocal Mode Test Study on stills, with the title ‘Laryngeal gestures and Laryngograph data associated with the four vocal modes as described in the Complete Vocal Technique method of singing teaching’. This study was presented by Cathrine Sadolin and Julian McGlashan at BVA ‘Choice for voice’ conference in London, England, 2010.