
After the laryngeal recognition the next thing we wanted to find out was if it was possible to identify the modes by the Laryngograph waveforms alone. It turned out that there are, to some extent, patterns in the waveform that could be used to identify the modes.
When looking at the videos from the endoscopy study in 2007 certain patterns are seen in the waveform within each mode. A still image for each of the modes was produced from the videos.
Each set of five (Neutral without air and Neutral with air were viewed separately) video images and waveforms were analysed by Julian McGlashan and Cathrine Sadolin and the appearance and relationship between the key features were agreed by consensus and documented. The consistent features were identified and schematic drawings produced with descriptive and explanatory text to aid pattern recognition.
The waveform is depicted as a line.
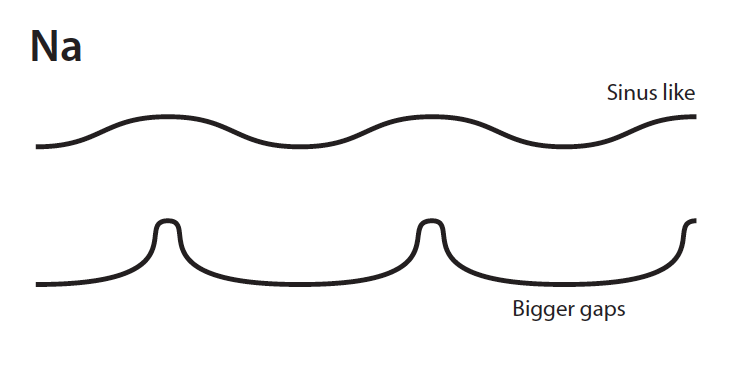
The Neutral with air laryngograph waveform has a sinusoidal shape. This is because there is no contact between the vocal folds due to the gap, which means that a lot of air is added to the sound and the volume is soft. In another example of Neutral with air there is the initial sinusoidal waveform but a brief upward spike indicating momentary closure of the vocal folds.
On the stills and videos the waveform is displayed with a green line in the bottom of the image.
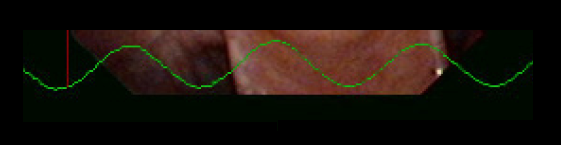
The laryngograph waveforms are more to be seen as patterns of progression from mode to mode, rather than absolutes. The waveforms differ a lot from person to person, some persons are having really weird waveforms, but still the patterns often show similar features. The progession in the patterns can be used as guidelines on how to identify the modes for an individual singer.
This information comes from a study Visual Vocal Mode Test Study on stills, with the title ‘Laryngeal gestures and Laryngograph data associated with the four vocal modes as described in the Complete Vocal Technique method of singing teaching’. This study was presented by Cathrine Sadolin and Julian McGlashan at BVA ‘Choice for voice’ conference in London, England, 2010.